|
|
Классические ошибки интерпретации количественных исследований7.2.1. Две базовые ошибки Две ошибки в интерпретации количественных исследований настолько распространены и принципиальны, что мы вынесли их в отдельный раздел. Первая базовая ошибка – игнорирование психологии . Суть ошибки заключается в убеждении, что опрос общественного мнения – исключительно социологический метод. Авторам, хотя они могут быть не очень объективны в силу своего психологического образования, представляется очевидным, что основная цель проведения опроса общественного мнения – это предсказание развития ситуации и выработка рекомендаций по коррекции этой ситуации. То есть описание положения дел во время исследования (а это, как минимум, ситуация 2 – 5-дневной давности к моменту получения отчета по исследованию) есть всего лишь задача для решения достижения этих целей. В то же время предсказание развития ситуации – это предсказание электорального поведения по мнению, а связь между мнением и поведением – предметное поле психологии, а не социологии. В целом, мнение авторов-психологов: дело социологов – констатировать ситуацию, давать рекомендации лучше психологам. А рекомендации – ключевой вопрос исследования, ведь так часто заказчики, получив отчет, говорят: «А что мне делать с этими данными?» Вторая базовая ошибка – игнорирование математики . Суть ее сводится к некритичному отношению к данным в перекрестных таблицах (они же «двумерки», они же «кроссы они же "в перекрестных таблицах (они же "не социологии.общественного мнения - это . х границ первоначальной нишилюди а. енится », они же «пересечения»). Ниже приведен типичный пример перекрестной таблицы – пересечение возраста и рейтинга партий. Ошибка игнорирования математики заключается в следующем. Большинство тех, кто всматривается в подобную таблицу, знает о существовании погрешности. Как правило, она указывается в начале отчета. Несколько меньшее количество людей знает, что эта погрешность зависит от размера генеральной совокупности и выборки, но не напрямую. Если конкретнее, то для генеральной совокупности более чем 100 000 человек нам достаточно опросить 1200-1500 респондентов, и погрешность не изменится. То есть и для всех избирателей России, и для крупного райцентра выборка в 1500 человек достаточна, За какую партию Вы скорее бы всего проголосовали, если бы выборы состоялись в ближайшее воскресенье? Август 2003, округ Госдумы ХХХ, выборка 1314 человек, квотированная по половозрастным стратам и району проживания
При анализе данных по региону, району или округу Госдумы, как только мы смотрим на перекрестную таблицу, видим аналог нескольких (в нашем примере – 6) выборок из нескольких генеральных совокупностей. Приведем расчеты пошагово. 1. Всего избирателей в округе = 450 000 человек. 2. Доля избирателей от 55 до 64 лет = 13%. 3. Количество избирателей 55 - 64 лет (13%*450’000) = 58 500 человек. 4. В выборку попало избирателей 55 - 64 лет (13% * 1314) = 171 человек. 5. Погрешность при выборке 171 человек из совокупности в 58 500 человек составляет ±7,48% (при 95% уровне достоверности).
То есть для данных по всей выборке погрешность составляет 2,7%, а для данных по возрастной группе «от 55 до 64 лет» – 7,5% (к примеру, – для группы «65 лет и старше» погрешность составляет 5,5%). Таким образом, нельзя воспринимать понятие «погрешность» как одну цифру в начале отчета. В хорошем отчете для каждой группы, по которой приводятся данные, должна быть отдельно указана погрешность.
Основное последствие ошибки игнорирования математики заключается в том, что отношение к цифрам становится слишком внимательным, вплоть до магического, и без должного понимания эти цифры могут нанести вред даже больший, чем полное отсутствие информации.
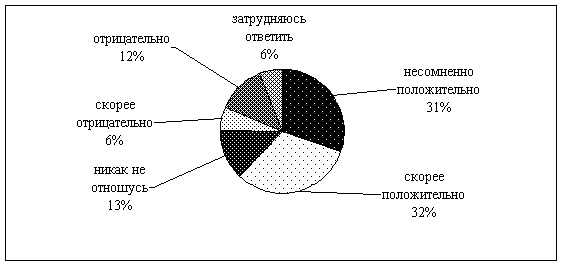
7.2.2. Основные ошибки Прежде всего, следует подчеркнуть, что здесь не идет речь о некорректном проведении опросов общественного мнения. Вопросы методологии и методики исследований достаточно тщательно разработаны, поэтому здесь они не рассматриваются. Мы говорим не об истинности выводов, а о валидности этих выводов относительно результатов исследования. Мы также не говорим о том, сознательно или несознательно делаются эти ошибки, преследуют ли авторы цели манипулирования аудиторией или нет. В данном параграфе мы хотим показать те ошибки, которые возникают при переводе «профессиональных цифр» в «непрофессиональные выводы». Мы постараемся продемонстрировать все выявленные нами ошибки на минимальном числе примеров, для того чтобы показать, что зачастую при интерпретации одного и того же вопроса встречается целый ряд ошибок. Как Вы относитесь к тому, чтобы губернатором Петербурга была женщина? Опрос АНО «Городской центр развития общественных связей», Санкт-Петербург, середина февраля 2003 года, репрезентативная выборка, 1255 человек
Объединяя такие ответы на вопросы, как «несомненно положительно» и «скорее положительно», авторы статьи говорят о том, что «более шестидесяти процентов горожан высказались за то, чтобы Петербургом руководила женщина». В одной этой фразе есть две ошибки. 1) Первую можно назвать «ложная сумма» . Причина ошибки «ложная сумма» заключается в суммировании результатов, измеренных в шкале, которая является промежуточной между ранговой и номинативной. Часто, интерпретируя результаты исследования, объединяют ответы типа «скорее да» и «точно да». При этом не учитывается то, что составители анкеты разбили «положительный ответ» на два не случайно, а исходя из понимания, что при выборе из трех альтернатив: «да», «нет» и «не знаю» - будет наблюдаться смещение ответов в связи с относительно высоким, но не первым рангом мотива голосования за женщину у респондента. Известно, что в каждый момент времени (за исключением экстремальных ситуаций) поведение человека определяется совокупностью мотивов, которые могут вступать в противоречие. Соответственно, если человек считает, что в целом хорошо, если городской администрацией будет руководить женщина, но при этом сам факт ее гендерной принадлежности не имеет решающего вклада в фактор «хороший губернатор – плохой губернатор», то он выберет ответ «скорее положительно». Таким образом, в данной категории оказываются люди, давшие этот ответ не по причине выявляемого отношения к проблеме, а по другим мотивам. То есть это ответ «мне все равно, какого пола губернатор» позитивно настроенного человека. 2) Следующая ошибка, приведенная в примере, – «думаю, но не делаю», «не “против”, но не “за”» . Суть ошибки состоит в подмене когнитивной и аффективной (эмоциональной) компонент установки компонентой регулятивной. Формулировка вопроса («Как вы относитесь…») выясняет исключительно первые два компонента. То есть человек может быть уверен, что женщина во главе города – это очень хорошо (и выбрать вариант ответа «несомненно положительно»), но в то же время это будет проявлением его когнитивной установки («я считаю, что женщина более мягкая, меньше стремится к власти»), а эмоциональный компонент установки по отношению к женщине-губернатору принципиально отличается («власть должна быть в руках мужчины», следствие подсознательной уверенности в правильности патриархального уклада). Если при этом эмоциональный компонент сильнее (что очень часто наблюдается в процессе принятия решения избирателем), то регулятивный компонент (установка на осуществление действия) будет соответствующим – избиратель проголосует против кандидата-женщины. Игра на данном противоречии часто используется в избирательных кампаниях при сборе подписей. Сборщики объясняют избирателям, что их подпись просто означает отсутствие возражения против выдвижения кандидата (на самом деле – поддержку выдвижения), а затем избиратель получает именное письмо с благодарностью за поддержку. 3) Ошибка «любят синих, кандидат - синий» . Эта ошибка не представлена в данном примере, но часто следует за приведенными выводами. Ошибка заключается в том, что, основываясь на невалидном выводе «60% за то, чтобы Петербургом руководила женщина», делается следующий шаг рассуждений: «если выдвинется только один кандидат женского пола, то 50-60% голосов ей обеспечено». Основание ошибки рассмотрено выше (в пункте 1) и заключается в невнимании к сложности структуры мотивов избирателя. 4) Ошибка «гиблые люди» . Часто те, кто не идет на выборы (или, скорее всего не пойдет на выборы), исключаются из анализа. На наш взгляд, это абсолютно неправильно, потому что 50% имеющих право голоса граждан РФ, которые почти никогда не ходят на выборы, - это тот ресурс, который почти не обрабатывается кандидатами. Две основные и взаимосвязанные причины этого – распространенность маркетингового подхода к построению кампании и презентизм мышления политтехнологов (презентизм – склонность представлять будущее подобным настоящему). Постоянное применение маркетингового подхода означает, что, если строить всю кампанию исходя из того, что нужно стабильно ходящим на выборы, то эта группа всегда будет неохваченной. Что же касается презентизма мышления политтехнологов, то нам представляется, что в случае постановки цели поднять явку на 10% за счет «привода» к участкам хорошо исследованной и относительно консолидированной группы избирателей, то можно сконцентрировать почти все эти 10% голосов в руках одного кандидата, что в большинстве случаев (по крайней мере – при выборах в законодательные органы власти) может стать решающим фактором. 5) Ошибка «нет погрешности» . Наиболее показательны ежемесячные партийные рейтинги, измеряемые ведущими федеральными исследовательскими компаниями (ВЦИОМ, ФОМ, Ромир- Monitoring ). Появление каждого рейтинга – информационный повод, служащий основанием для множества публикаций в СМИ. И многие журналисты и аналитики начинают говорить о том, что «Рейтинг «Единой России» упал на 2,5%, а КПРФ - вырос на 2%. Это свидетельствует о росте недовольства общества по поводу замораживания реформ, отсутствия реальных улучшений, что и привело к перетеканию избирателей от президентской партии к оппозиционерам». Очевидно, что при погрешности 2% говорить о каких-либо изменениях в структуре партийных симпатий избирателей невозможно. Тем более не следует привязывать эти изменения к каким-то конкретным решениям правительства. 6) Ошибка «двойная погрешность» . В некотором смысле данная ошибка противоположна предыдущей. Сравнивая рейтинги кандидатов, некоторые журналисты упрекают своих коллег в предыдущей ошибке. Они говорят о том, что если рейтинг одного кандидата 23%, а другого –18% при 3% погрешности измерения, то это значит, что их рейтинги не отличаются, так как у одного рейтинг может колебаться от 20% до 26%, а у другого – от 15% до 21%. Поскольку эти интервалы перекрываются, то, следовательно, отличий нет. Однако следует указать на то, что не все значения в пределах интервала, определяемого погрешностью, равновероятны. То есть значение 20,1% для первого кандидата менее вероятно, чем значение 22,5%. Точно так же и для второго. Поэтому, сравнивая рейтинги двух кандидатов и опираясь на указанные значения погрешности измерения (3%) и уровня значимости (95%), можно говорить о том, что рейтинги кандидатов различаются с вероятностью 95%, если их разность более 3%. Кроме того, для каждой пары значений, отличающихся менее чем на 3%, возможно вычислить ту вероятность, с которой одно значение превысит другое в генеральной совокупности. 7) Ошибка «нет затруднившихся» . Похоже, что очень часто ответ «затрудняюсь ответить» считается «непригодным» для анализа. Даже если около 30-40% избирателей еще не определились с выбором, делаются выводы о шансах кандидатов, исходя из имеющихся рейтингов. Хотя очевидно, что при отсутствии 1-2 явных лидеров (то есть когда 2 кандидата имеют рейтинг около 20%, или один – около 30%) высока вероятность того факта, что не определившиеся – это не только те избиратели, которые делают выбор в последний момент (по нашим оценкам от 3-5 до 10-15% в зависимости от явки), но, вполне вероятно, и не охваченный уже «раскрученными» кандидатами какой-то из «базовых электоратов». Соответственно, появление кандидата, играющего на неохваченном поле, сразу даст шанс вырваться в лидеры (под «появлением» в данном случае подразумевается раскрутка до 30-40% уровня известности). 8) Ошибка «все всех знают» . Когда рейтинг известности основных кандидатов не превышает 20%, делать выводы об их шансах, основываясь на рейтинге предпочтений, невозможно (в данном случае под основными имеются в виду кандидаты, потенциально располагающие финансовым, административным и личным-электоральным ресурсами). В интересной форме схожую ошибку можно встретить у профессиональных социологов. Объясняя значительные несоответствия данных опросов незадолго до выборов и результатов голосования, они апеллируют к склонности опрашиваемых высказывать социально одобряемую точку зрения, то есть постулируется то, что избиратель уже знает, за кого будет голосовать. Хотя феномен социально одобряемых ответов существует, однако не следует преувеличивать его значение. 9) Ошибка «явка не важна» . Все прогнозы строятся, исходя из определенного уровня явки, при этом, как правило, не указываемого. Иногда это связано с особенностью построения исследования, подразумевающего опрос исключительно тех, кто точно придет голосовать. 10) Ошибка «ложная гомогенность» , «все относится ко всем» . Ошибка связана с тем, что анализируются распределения ответов только по всей выборке в целом (одномерные распределения), а затем результаты переносятся на отдельные группы. Типичный пример: подсчитывается рейтинг актуальных проблем округа или региона, а затем делается вывод о том, что самые важные для населения в целом проблемы именно в таком же порядке значимы для каждого конкретного человека. То есть правильная интерпретация не «каждого человека больше всего волнует проблема ХХХ», а «большинство населения волнует проблема ХХХ». При кажущейся очевидности, многие исследователи совершают эту ошибку. 11) « Обмен рейтингами – обмен людьми ». Данная ошибка подразумевает, что при сравнении двух последовательно проведенных опросов падение рейтинга одного кандидата/партии и повышение другого, на примерно равную величину, описывается как перетекание электората (то есть изменение электоральных предпочтений) от одного к другому. Если рейтинг одного кандидата был 40%, а другого - 60%, а через месяц у них рейтинги по 50%, то без дополнительных вопросов в исследовании мы не сможем быть уверены, что на самом деле миграция сторонников была значительно больше, а 10% – это баланс этой миграции.
7.2.3. Классификация ошибок Мы предлагаем некоторую классификацию ошибок, исходя из определения той сферы, в которой при операциях происходит ошибка. Первый тип – «ошибки математики» , они связаны с непониманием взаимозависимостей между численными показателями результатов опроса, несоответствием между делением респондентов на группы, с «логической некорректностью». Второй тип – «ошибки психологии» , они связаны с непониманием структуры компонентов психологии человека и их взаимосвязей. Ошибки математики: - игнорирование математики ; - «нет затруднившихся»; - «все всех знают»; - «явка не важна»; - «нет погрешности»; - двойная погрешность; - «обмен рейтингами – обмен людьми»; - «ложная гомогенность», «все относится ко всем». Ошибки психологии («структура мотивов»): - игнорирование психологии ; - «ложная сумма»; - «думаю, но не делаю», «не “против”, но не “за”»; - «любят синих, кандидат синий»; - «гиблые люди».
Просмотров: 1940 Категория: Другие новости по теме: --- Код для вставки на сайт или в блог: Код для вставки в форум (BBCode): Прямая ссылка на эту публикацию:
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||